Ten Ways to Accelerate AI Training with Synthetic Data

AI thrives on data. Obtaining quality training data is often a slow, error-prone, and costly process. Synthetic sensor data provides a viable alternative, enabling perception teams to reduce their data acquisition cycles from months to hours. In this post, we explore ten reasons why synthetic data will overtake real data for AI development.
What is Synthetic Data?
Synthetic data is generated by a computer program or algorithm rather than being collected from real-world sources. It is often used in machine learning and other fields to train algorithms and models since it can be generated in large quantities and is easily controlled.

In the realm of AI perception, synthetic data can be utilized to generate highly realistic, diverse, and labeled datasets for a variety of machine learning tasks such as object recognition, semantic segmentation, and depth estimation. According to Gartner, by 2024, synthetic data is expected to make up 60% of the data used for the development of AI and analytics projects.
This artificially generated data is taking the AI world by storm, providing a reliable and controllable source for training machine learning models and reducing the need for data collection from the real world. Here are ten reasons why synthetic data should be a key component of your perception training and testing strategy:
1. AI with the Speed of Silicon, not Humans.
Synthetic data can lead to ~180X faster perception development cycles [1]. A typical data acquisition project involves lengthy collection, labeling, and quality assurance steps. Generating production quality labels usually requires a well-trained workforce to handle it, not to mention that some labels are almost impossible to obtain manually (e.g., optical flow and depth).
Alternatively, we can generate accurately labeled and diverse synthetic data at a massive scale in a couple of hours instead of months. This allows rapid iteration and tweaking in a way that’s not possible with real world data.

2. High Fidelity
The “domain gap” between real and synthetic data is usually a major barrier to achieving good results from trained ML models. This gap happens for different reasons, including the visual differences between both datasets. High fidelity content and accurate sensor simulations are vital to reducing such a gap.
With Parallel Domain, you can select from a wide variety of common and accurately simulated camera, LiDAR, and radar sensors, or tune your own configuration. Our expert content artists use cutting edge CGI with procedural generation to produce a wide variety of realistic agents, regions, and environmental conditions.
In addition, we leverage various AI-based style transfer techniques to bridge the Sim2Real gap.

3. Labels that Work
Human labeling is usually error-prone. Synthetic data comes with accurate labels for imagery and lidar, including 2D and 3D bounding boxes, semantic and instance segmentation, depth, optical flow, motion vectors, keypoints, and more.
Synthetic data also offers deep control and flexibility for altering labels at a button click, allowing you to customize the labels to suit your needs and avoid certain pitfalls. This can include simulating imperfections and variations present in real-world data, such as in-object gaps with the same semantic label. Doing so should lead to improving the reliability and robustness of your ML models when deployed to production.

4. Matching and Configuring Diversity
The real world is complicated and diverse; synthetic data needs to be on par to better enable machine learning models. Parallel Domain’s content is highly diverse on multiple levels: locations, urban settings, environmental conditions, assets, and scenarios.
For locations: we support different geographies, including the United States, Europe, and Asia. For urban settings: users can generate data for various highways, suburban, or urban scenes. Scenes come with different selections of buildings, houses, roads, props, terrain, and vegetation.
We also provide the ability to generate more than 3000 types of assets, with technically infinite permutations like color assignment and accessories that are added at simulation time. Those assets include pedestrians, vehicles, road furniture, animals, traffic lights, and more.

5. Solving for the Long Tail
Training perception models to recognize infrequent scenarios is challenging because data for rare events is often scarce. For example, consider partially occluded pedestrians or vehicles suddenly exiting residential driveways. How many samples of these scenarios can we find in real world data? Tens, or maybe hundreds? That’s not enough to feed starving AI models.
One way to address this problem is to use synthetic data engines to generate such rare scenarios. This approach can be particularly effective for edge cases because it allows the model to learn from a wide variety of data that would be otherwise unavailable.
Parallel Domain users can easily choose to include different types of rare cases or objects in their generated data; examples include: jaywalking, vehicle lights for emergency vehicles or school buses, vulnerable road users, parking scenarios, construction sites, road debris, lane switching, and more.

6. An API Away
Synthetic data provides a great deal of flexibility that is not available with manual collection methods. Because it is artificially generated, we can program whatever output we wish to have in our training data. It can be customized and adapted to different AI projects. Developers can generate a wide range of data scenarios and experiment with different parameters until they find the best solution.
Programming synthetic data usually takes place through an API or a graphical user interface. Parallel Domain provides both plus and the ability to integrate real-time data generation with daily simulation testing.
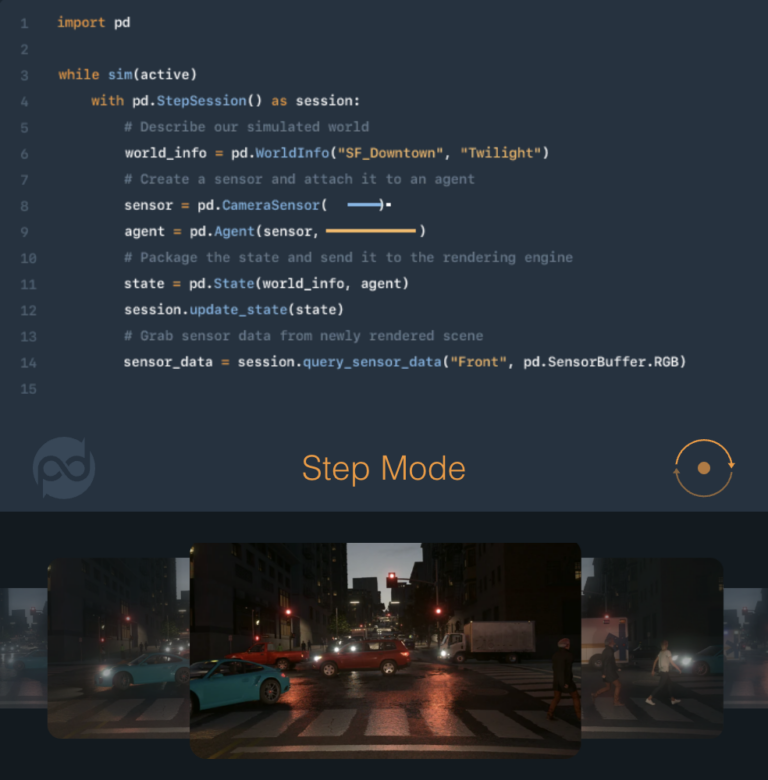
7. Multi-purpose
Using synthetic visual data for training is the most common use case today. However, we can also use it for validation, testing, and new hardware exploration.
For testing: autonomous system developers usually need to run daily regression tests using their simulation stack. One challenge they typically face is rendering and visualizing the simulated scenarios to enable perception testing. Parallel Domain customers can do this today via the Step API.
Some of our customers have been using synthetic data to support new sensor research and development. Before investing in building a new LiDAR sensor – for example, they can simulate data this sensor would generate and see if it moves the needle on their perception models’ performance.

8. Ethical
Removing personal information from collected data is costly and error-prone; examples include human faces and license plate numbers. Identities and objects in synthetic worlds are all virtual, eliminating privacy risks for both individuals and communities.
Similarly, developers could leverage the same methods to mitigate recognized biases. Synthetic data engines provide the controls needed to create well-balanced datasets. With these “knobs”, we can ensure different objects and agents are sufficiently presented and alleviate biases related to gender, ethnicity, socioeconomic status, age, and more.
This is particularly important for safety-critical applications like autonomous vehicles, robots, and drones. Ethical data enables developers to take proactive steps to ensure their systems are unbiased and capable of operating safely and effectively in the real world, all while protecting the privacy and equity of individuals and communities.

9. It Works
There’s plenty of evidence that synthetic data is contributing significant value to perception models performance. From building smarter autonomous vehicles to helping drones deliver packages into your yard and augmenting human vision with smartphones – our growing set of customers, including Google, Continental, Woven Planet, Toyota Research Institute, and many more, are finding synthetic data critical for scaling the AI that powers their vision and perception systems.
Published research shows how Parallel Domain data improved rare class detection on KITTI and nulmages, beat state of the art in multi-object tracking, and more (1, 2, 3, 4).
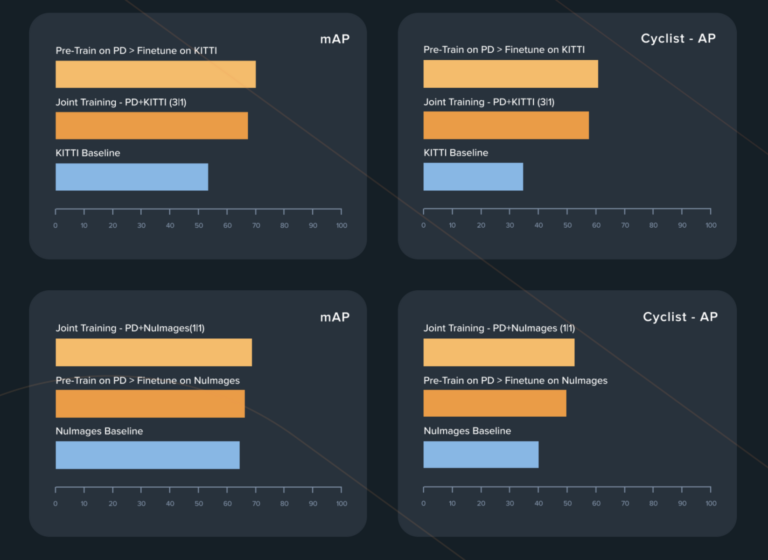
10. Rapid Prototyping
Synthetic data is key to unlocking rapid AI prototyping. With just a few lines of code, developers can easily change various configurations and generate tailored data to explore ideal labeling and training/testing strategies, identify model gaps, and optimize production tactics – without relying on lengthy data collection and labeling cycles.
Check out this in-depth interview if you’d like to know more about how Toyota Research Institute uses synthetic data to train better computer vision models. If you’d like to try out a sample of synthetic data yourself, go ahead and download our open dataset. And, If you are a perception team ready to break free from the constraints of real-world data – let’s have a conversation!
References
[1] Many of our customers have reported that it typically takes them around three months to gather and label high-quality training data for perception tasks such as semantic segmentation and object detection. By utilizing Parallel Domain to generate equivalent synthetic datasets, we have been able to significantly reduce this time to just 3-6 hours – a roughly 180-fold increase in speed


