Not all Synthetic Datasets are Created Equal

Parallel Domain data improves unsupervised domain adaptation performance by 30% vs. GTA with no changes to the model architecture.
Training semantic segmentation models requires a lot of data to be labeled pixel by pixel. Manually labeling a single image for semantic segmentation can take over an hour [1] and model training requires thousands of images. Pre-labelled Synthetic data provides a faster alternative, however – results might be impacted due the domain gap between real and synthetic data.
Unsupervised domain adaptation models could be leveraged to bridge this gap, but performance is limited by the low quality and relevance of most synthetic data and these models are rarely usable. What if we could design a dataset to improve model performance in specific, real-world settings?


In this post, we will:
- Explain unsupervised domain adaptation and why it is so powerful.
- Identify some of the problems with off-the-shelf synthetic datasets that hurt model performance.
- Show how to tailor a synthetic dataset to your task that addresses each of those problems.
- Quantify the impact of better synthetic data on models applied to real-world semantic segmentation.
Domain Adaptation: Training Models to Generalize
Synthetic data offers a number of benefits: it can be generated more quickly and inexpensively than real-world data; it requires no human labeling; it can be tailored to address specific tasks and settings. Training with synthetic data, however, does add one new hurdle: because synthetic data often differs from real world data in subtle ways, a domain gap exists between them. Domain gaps are not unique to synthetic data; they also exist between real world datasets collected in urban and rural settings, in different cities, by different sensor configurations, or at different times of the day. Bridging these gaps – with novel architectures or training techniques – is known as domain adaptation (DA).
In a typical DA setting, a small amount of labeled data is available from the target domain (real world data), which can then be used to fine-tune models trained on data from the source domain (synthetic data). For semantic segmentation, however, labeling is so expensive and time-consuming that there is interest in training models without any labeled training data from the target domain. This task is known as unsupervised adaptation (UDA). The potential of a viable UDA method is clear: training performant semantic segmentation models without spending time and resources on collection and labeling.
There are many different approaches to UDA but most take the same high-level approach: select a standard model for the desired task and add a regularization term that pushes the model toward domain invariance. In order to generalize from the source domain to the target domain, the model must learn to extract features from both domains in similar ways. Generalization is also easier if the synthetic data more closely mirrors the real-world data.
Improving Domain Adaptation Through Improved Data
“Most benchmarks provide a fixed set of data and invite researchers to iterate on the code … perhaps it’s time to hold the code fixed and invite researchers to improve the data,” Andrew Ng, The Batch
UDA is an active area of research, but even state of the art models are limited by the contents of the synthetic data they are trained on. Most UDA research for driving focuses on the GTA->Cityscapes benchmark, where the source dataset, GTA [3], is a collection of images and annotations extracted from the video game Grand Theft Auto V and the target dataset, Cityscapes [4], is real-world driving data from multiple German cities. While GTA is a high-resolution, richly detailed virtual world, it differs from Cityscapes in a number of ways:
- The camera intrinsics and extrinsics do not match.
- Semantic labels are precisely labeled pixel-by-pixel in GTA but coarsely hand-drawn in Cityscapes.
- GTA is modeled after southern California while Cityscapes is a collection of German cities.
- The class distributions (vehicles, traffic signs, pedestrians) are vastly different.


Each of these discrepancies increases the domain gap and worsens model performance. What if, instead of trying to work around the domain gap with complex model architectures, we just generated a better synthetic dataset? Spoiler alert: we actually did – using Parallel Domain!
Experiment
The following experiment shows the significant performance boost made possible by directly reducing the synthetic-real domain gap, with no changes to the model architecture. We will focus on the semantic segmentation task and a UDA architecture called Adversarial Entropy Minimization, or ADVENT [2]. ADVENT uses a discriminator during training that pushes the model to make predictions with the same entropy on real and synthetic images (entropy measures the class prediction confidence). We chose ADVENT because it is easy to interpret and implement but newer, more powerful UDA methods exist, such as GUDA [5] and DAFormer [6].
We generated three datasets, each incrementally improving on GTA in specific ways:
- PD v1 matches the Cityscapes camera intrinsics and extrinsics exactly, but otherwise mirrors GTA in scene and class distribution.
- PD v2 simplifies the semantic maps from PD’s pixel-perfect maps to a coarser map that adheres closer to real-world human labeling (e.g. filling in holes in fences and trees).
- PD v3 matches the Cityscapes setting (more urban and more vegetation than GTA) and uses a more uniform class distribution with increased rare objects like bicycles, buses, and traffic signs.


All PD datasets are about the same size as GTA. We will see below how each dataset improvement translates to better model performance.
Results
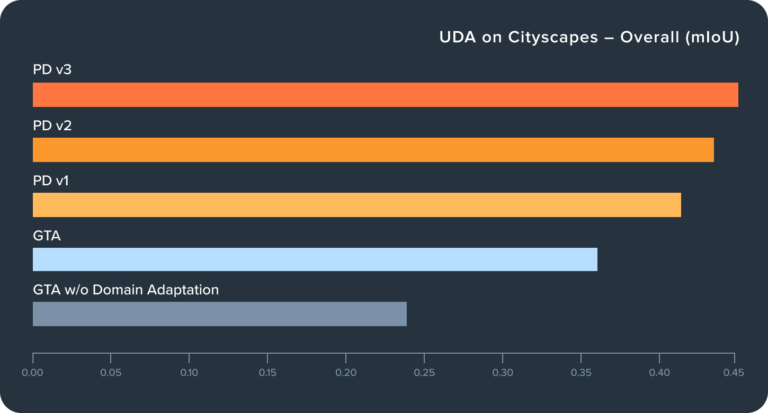
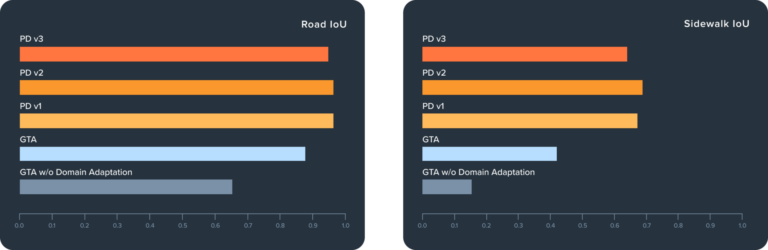
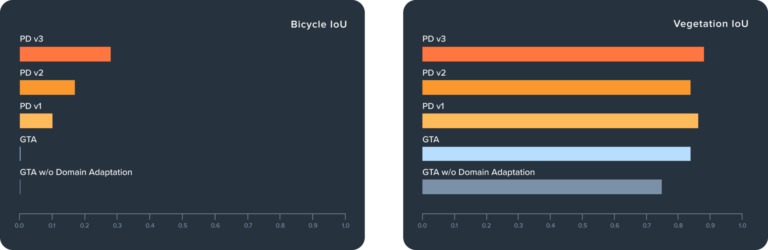
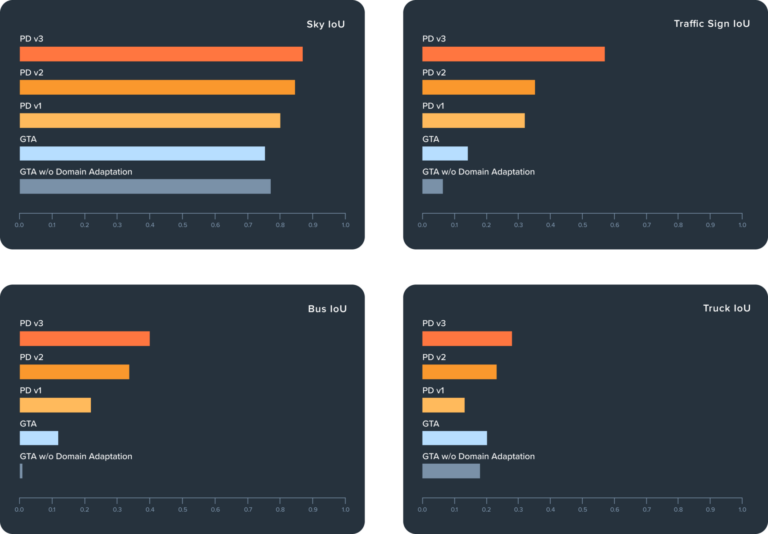
Figure 4 shows the impact of domain adaptation (ADVENT in this case) and the further improvement of better aligned synthetic data. Applying ADVENT to GTA improves mIoU from 0.24 to 0.36 (50%), a significant improvement in line with published UDA results. Using the same ADVENT model and training regime but tailoring the data as described above, we see PD datasets v1, v2, and v3 improve a further 17%, 25%, and 30%, respectively. This is a dramatic improvement over and above a recent technique like ADVENT. For comparison, it took almost 3 years of research for state-of-the art UDA architectures to improve on ADVENT by that amount [6]. We can see specifically how the model improves from the class-level metrics in Figures 5-7.
Conclusion
Collecting and labeling real-world data for semantic segmentation is expensive and time consuming. Training with synthetic data is faster and more economical, but only if the synthetic data is realistic and well designed. Techniques like unsupervised domain adaptation that may not be viable when trained on off-the-shelf datasets like GTA, are unlocked when trained on realistic data specifically customized for the task using Parallel Domain synthetic data platform.
If you’d like to get access to the Parallel Domain datasets used in this article, please get in touch with us!
References
[1] The cityscapes dataset for semantic urban scene understanding
[2] Adversarial entropy minimization for domain adaptation in semantic segmentation
[3] Playing for data: Ground truth from computer games
[4] The cityscapes dataset for semantic urban scene understanding
[5] Geometric unsupervised domain adaptation for semantic segmentation


