Beating the State of the Art in Object Tracking with Synthetic Data

Machine learning models for object tracking have improved significantly in the past few years, but the current leading approaches continue to fail critically during common occlusion cases. Picture the following scenario: we are about to turn left after an oncoming van passes through the intersection, but we pause before making the turn. Just moments before the van obstructed our view, we saw a bicyclist on the other side riding through the intersection. As human drivers, we deal with this situation all of the time – we understand the concept of object permanence and we remember that the bicyclist is there. However, even the best modern deep learning models tend to fail in these types of cases, forgetting that objects exist almost immediately after they are no longer directly visible. In this article, we will discuss how Toyota Research Institute (TRI) was able to use synthetic data from Parallel Domain to beat the state of the art in multi-object tracking in exactly these types of important and challenging scenarios.

How often do these occlusion cases occur?
It turns out that they are very common and current models underperform when encountering occluded objects. Take the MOTChallenge benchmark for example. On the left side of the graph below, Bergmann et al., show that the occurrence of objects that are mostly occluded (the thick red bars) comprise a substantial percentage of the dataset, while the top performing models (the thin colored bars) often achieve accuracies of less than 5% when visibility is at or below 20%.

Why have models historically failed to track objects through occlusions?
It turns out that shortcomings with both data and model architecture have been holding back performance in high occlusion cases. In order to achieve their state of the art results, TRI needed to overcome the following problems:
- Human labelers make mistakes, sometimes miscategorizing or failing to label an object entirely. Model performance is bounded by the accuracy of your labels, and it turns out that humans make a lot of mistakes labeling objects that they can’t see.
- The challenge of object re-identification with human labeling leads to a “maximum occlusion gap”, defined as the time after which an object doesn’t need to be correctly tracked. This limits the maximum occlusion time for which a model can be trained.
- Humans have to guess the occluded trajectory in a real-world dataset, or software attempts to interpolate between sightings, but both of these approaches introduce label inaccuracy because a 3D trajectory projected into the 2D image plane often produces nonlinear motion.
- Both collection and labeling of real-world data are costly and time consuming, severely limiting the speed at which a team can iterate during development and then scale their new approach to production.
- The model architecture needs to be able to remember that a previously observed object might reappear later as well as reason about the nonlinear trajectory of that object when it is not visible.
Parallel Domain data is an ideal solution for solving these problems because our data:
- Guarantees that every object is labeled, ensuring that missed or incorrect labels no longer contribute to model error.
- Can track an object for an arbitrary length of time, enabling a model to track fully through an occlusion, beyond what is feasible for humans to annotate.
- Provides precise trajectory and orientation information, removing all error-prone guesswork in labeling occluded objects.
- Is massively scalable, significantly reducing the time and cost to obtain training-ready data relative to real-world collection and labeling.
TRI combined their model architecture innovations with synthetic data from the Parallel Domain platform to publish a paper titled “Learning to Track with Object Permanence” (Tokmakov et al., 2021) that establishes the new state of the art in tracking objects through occlusions.
Learning to Track with Object Permanence
In order to track objects through occlusions, models need to understand that objects still exist even if they’re not visible. “[This] is known to cognitive scientists as object permanence, and is observed in infants at a very early age. In adults, understanding that occluded objects do not disappear is important for tasks like driving” (Tokmakov et al. 2021). A key requirement to learn object permanence in supervised learning is to have labels for objects regardless of whether or not they are occluded. To accomplish this, TRI utilized Parallel Domain’s state of the art synthetic data platform to procedurally generate large, high-fidelity datasets with accurate ground truth labels. This includes occlusion estimated 2D bounding boxes tracked through the whole scene (with partial and full occlusions). Additionally, the Parallel Domain platform gives TRI control over the density and duration of these occlusions, enabling much faster iteration during development.
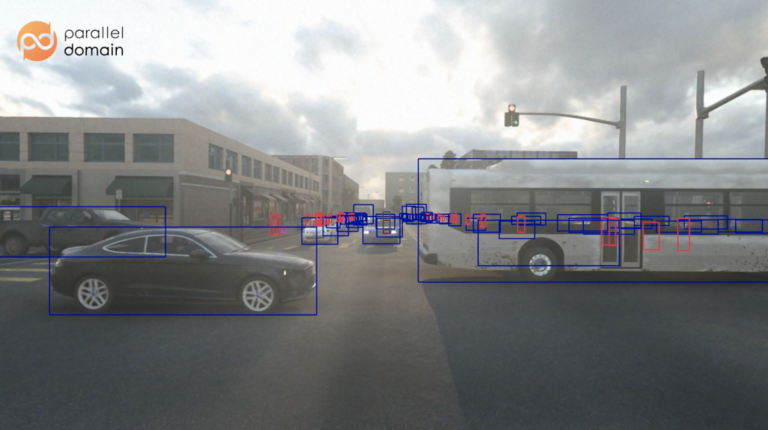
If you are curious what Parallel Domain’s data looks like, check out the Web-based Visualizer!
Prior Work
“Tracking Objects as Points” (Zhou et al., 2020) describes an approach called CenterTrack that detects boxes as well as a 2D displacement vector pointing to the object’s location in the previous frame. In order to predict the displacement vector of the current frame, the previous frame as well as a heatmap of tracked object positions are passed to the model.

By adding the displacement vector to the detected box position you can get the estimated position of the objects on the previous frame. To track boxes, one can match the nearest neighbors in a greedy manner by calculating the distance between the detections of the previous frames and the projected detections of the current frame.
TRI’s Approach
One of the primary model architecture enhancements that TRI made was to add a convolutional gated recurrent unit (Conv GRU) that enables their model to aggregate a representation of persistent objects and their movement over time, establishing this object permanence capability. Instead of passing multiple frames and a heat map as the input to the model (as was done in CenterTrack), TRI passes single images sequentially to their backbone network. The backbone network generates feature maps that are then passed to the Conv GRU, followed by detection heads that, similar to (Zhou et al., 2020), predict a heat map at the pixel positions where objects are located as well as their sizes and the offset to the previous frame (see below image). Additionally TRI adds a head that predicts “..whether the object center at a particular location corresponds to a visible, or a fully occluded instance” (Tokmakov et al., 2021). This explicitly assures that the occlusion information is available in the models feature space making this information also available to object size and location heads.

To evaluate their approach, TRI trained on different combinations of Parallel Domain’s synthetic Dataset and the KITTI Dataset while evaluating on KITTI. To jointly train with real and synthetic samples, the real samples are limited to frames where objects are not occluded since they miss labels for occluded cases. But this also enables them to train jointly on real and PD data samples, empowering their backbone network to learn domain invariant features and thereby helping to bridge the domain gap. The result is a model that outperforms all other benchmarks when tested on the real-world KITTI data. This point is worth re-emphasizing: TRI’s model architecture was able to utilize PD + KITTI data to outperform all previous leading model benchmarks in object tracking (see the below Table 4).

Further, Table 3 to the right shows results of the TRI approach compared to CenterTrack trained on different datasets (PD = Parallel Domain data). Comparing the first and the last row of the above Table one can see that by adding synthetic labels (including fully occluded objects) to the existing CenterTrack (Zhou et al., 2020) approach, the model gains +7.8% mAP (and it is worth noting that Person AP improved by a double-digit 12.2%). This shows how significant the improvements are one can get by augmenting your existing training set with the right synthetic data.

Comparing the second to last row (TRI’s architecture) to the last row (CenterTrack architecture), you can see how the TRI’s architecture achieves better precision on the same data, yielding another +6.1 mAP compared to CenterTrack which also outperforms the state of the art on KITTI and MOT17.
One very interesting thing to point out is the second line on Table 3. It shows that TRI’s new approach trained on only PD data already surpasses the performance of CenterTrack, trained on KITTI only, by +10 AP on Cars while just being 1.2 AP points shy on Pedestrians. This is quite significant considering that this model has never seen a real data sample of its target domain and also highlights the efficacy of Parallel Domain data!

Recapping, we showed how TRI established a new state of the art in multi-object tracking by utilizing Parallel Domain synthetic data with a modified CenterTrack architecture that accounts for the full spatio-temporal history of objects across video sequences.
Tracking is just one way to make use of synthetic data to improve your perception and vision models. Future posts will detail more ways that machine learning developers are pioneering the use of synthetic data to establish the new state of the art. If you are looking to use synthetic data as part of your model development cycle, contact us!
Bibliography
Bergmann, P., Meinhardt, T., & Leal-Taixe, L. (2019). Tracking without bells and whistles. https://arxiv.org/pdf/1903.05625.pdf
Tokmakov, P., Li, J., Burgard, W., & Gaidon, A. (2021). Learning to Track with Object Permanence. https://arxiv.org/pdf/2103.14258.pdf
Zhou, X., Koltun, V., & Krähenbühl, P. (2020). Tracking Objects as Points. https://arxiv.org/pdf/2004.01177.pdf


